高解像度降水ナウキャストと5分毎250mメッシュ全国合成レーダー降水強度GPV
高解像度降水ナウキャストと5分毎250mメッシュ全国合成レーダー降水強度GPV(5分毎全国合成レーダー降水強度・エコー頂高度GPVの一部)(以下、250mレーダーデータ)は、250m格子(陸上と沿岸付近)と1km格子(その他海上)の領域があります。(下図:250m格子と1km格子の対象領域、気象庁の配信資料に関する技術情報第568号、別図1より)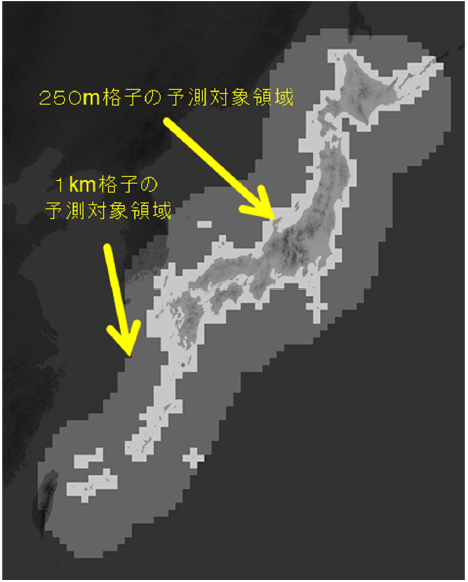 マップ等にプロットする場合は、各領域の位置を適切に配置する必要があります。また、データ容量が非常に大きいため、利用したい領域だけを抽出できると便利です。
マップ等にプロットする場合は、各領域の位置を適切に配置する必要があります。また、データ容量が非常に大きいため、利用したい領域だけを抽出できると便利です。領域の情報
250mレーダーデータは、下図(高解像度降水ナウキャストの例:気象庁の配信資料に関する仕様No.11802より抜粋)のように、GRIB2形式の第3節から第7節を領域分繰り返すというフォーマットになっています。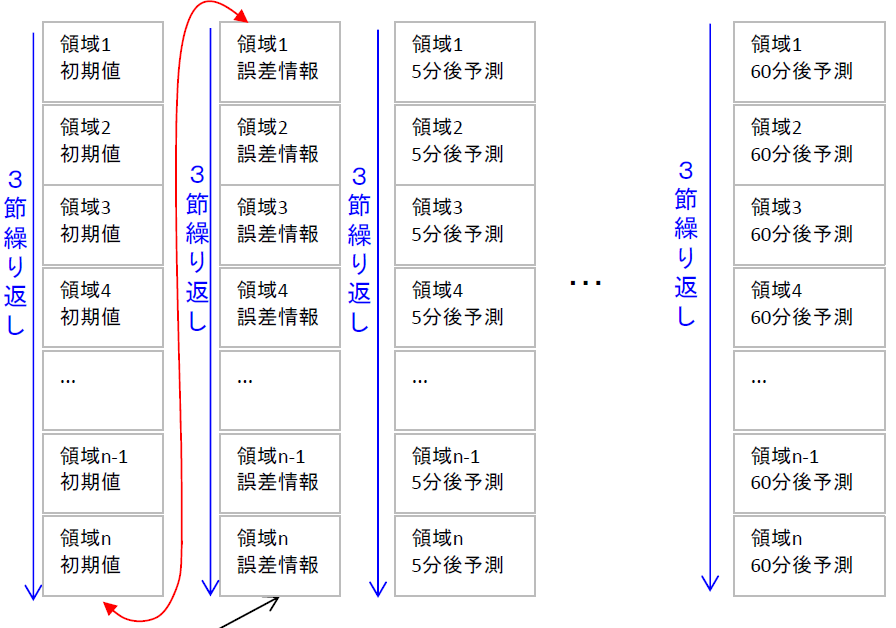 (5分毎250mメッシュ全国合成レーダー降水強度GPVは初期値の部分に相当し、領域n個の繰り返し)
(5分毎250mメッシュ全国合成レーダー降水強度GPVは初期値の部分に相当し、領域n個の繰り返し)領域の情報は、GRIB2形式の第3節(格子系定義節)に格納されています。
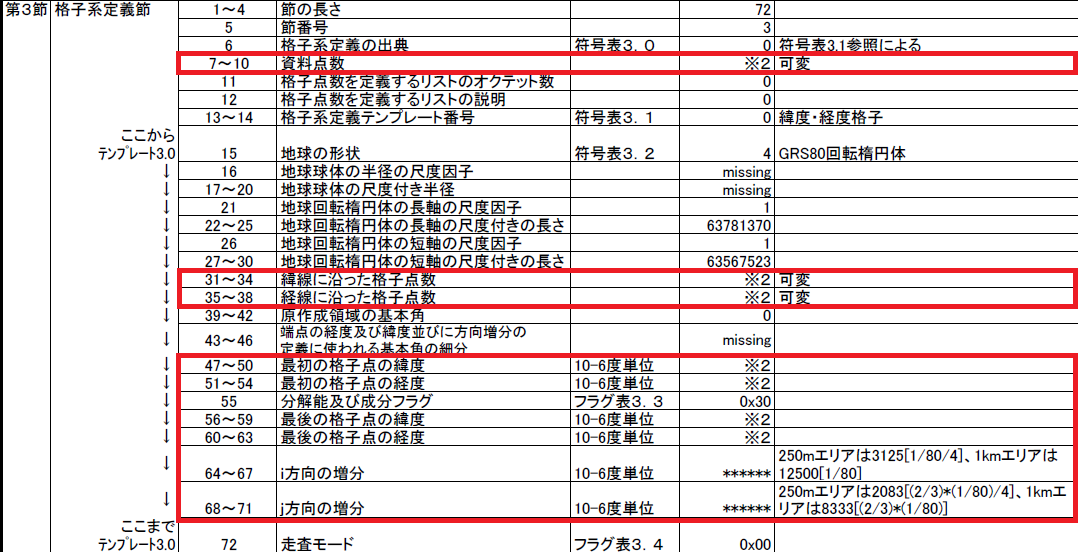 250m格子と1km格子で格納される値は、"今のところ通常は"以下のようになっています。
250m格子と1km格子で格納される値は、"今のところ通常は"以下のようになっています。| 第3節要素 | 250m格子 | 1km格子 |
|---|---|---|
| 資料点数 | 25600 | 1600 |
| 緯線に沿った格子点数 | 160 | 40 |
| 経線に沿った格子点数 | 160 | 40 |
| i方向の増分 | 0.003125 | 0.012500 |
| j方向の増分 | 0.002083 | 0.008333 |
第3節の格納値はwgrib2の-gridオプションでも簡単に確認することができます。以下はコマンド例です。
wgrib2 -grid Z__C_RJTD_20220225072500_NOWC_GPV_Ggis0p25km_Prr05lv_Aper5min_FH0000-0030_grib2.bin
-- 1km格子部分の例 --
lat-lon grid:(40 x 40) units 1e-06 input WE:NS output WE:SN res 48
lat 46.662500 to 46.337500 by 0.008333
lon 140.006250 to 140.493750 by 0.012500 #points=1600
-- 250m格子部分の例 --
lat-lon grid:(160 x 160) units 1e-06 input WE:NS output WE:SN res 48
lat 45.665625 to 45.334375 by 0.002083
lon 140.501563 to 140.998438 by 0.003125 #points=25600
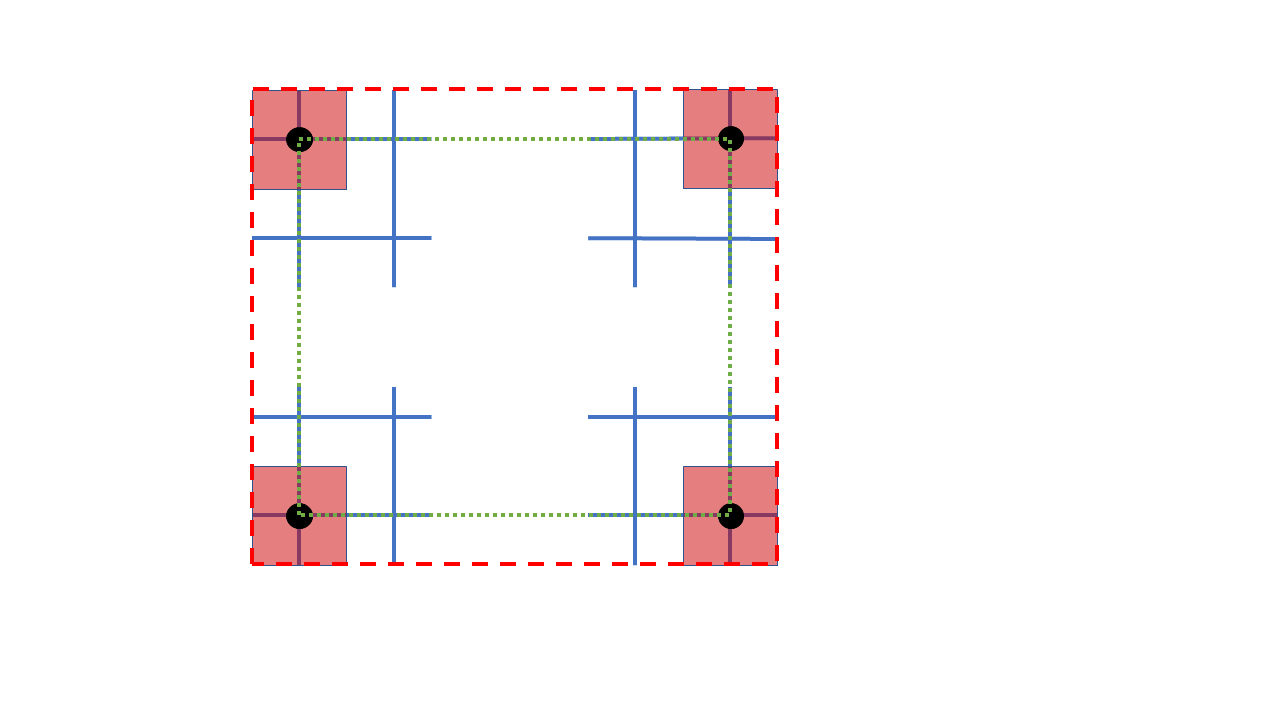 上図はそのイメージですが、メッシュの中央(黒丸)の位置がその緯度経度であるため、プロットするメッシュ(赤四角形)は緯度経度で示される領域(緑点線)の半メッシュ外側(赤破線)までとなり、隙間なく埋められることがわかります。
上図はそのイメージですが、メッシュの中央(黒丸)の位置がその緯度経度であるため、プロットするメッシュ(赤四角形)は緯度経度で示される領域(緑点線)の半メッシュ外側(赤破線)までとなり、隙間なく埋められることがわかります。指定領域の抽出
250mレーダーデータは、第3節(格子系定義節)も繰り返すというフォーマットのため、以前紹介したwgrib2の-ijboxや-small_gribで切り出すことができません。とはいえ、全ての領域をバイナリ(-ieee)やCSV(-csv)出力すると、とんでもないデータ容量のファイルが出来上がってしまいます。
まずは、繰り返し単位の領域毎に抜き出してみましょう。
各250mレーダーデータによって出力内容は異なりますが、wgrib2コマンドをデータファイルだけ引数にして実行すると(以下、コマンド例)、「:」で区切られた1カラム目に「1.N」の数字が共通して出力されます。
wgrib2 -grid Z__C_RJTD_20220225072500_NOWC_GPV_Ggis0p25km_Prr05lv_Aper5min_FH0000-0030_grib2.bin
1.1:0:d=2022022507:APCP:surface:-5 min fcst:
1.2:0:d=2022022507:APCP:surface:-5 min fcst:
1.3:0:d=2022022507:APCP:surface:-5 min fcst:
・・・
1.24820:0:d=2022022507:APCP:surface:55 min fcst:
1.24821:0:d=2022022507:APCP:surface:55 min fcst:
1.24822:0:d=2022022507:APCP:surface:55 min fcst:
1つの時刻で、領域の数は1773個です(ただし、これも可変と考える必要があります。ここでは説明を簡単にするため固定として進めます。)。
5分毎250mメッシュ全国合成レーダー降水強度GPVは、時刻が1つしかないので、
wgrib2 Z__C_RJTD_20220329060500_RDR_GPV_Ggis0p25km_Pri60lv_Aper5min_ANAL_grib2.bin -match "1\.N:" -csv radar250m.csv
とすると領域を1つ抽出できます。(出力オプションは-csvの他にも可能と思いますので、試してみてください。)
高解像度降水ナウキャストの場合は、誤差情報と予報値があるため、その時間ステップ分飛ばして「N+1773×(時間ステップ-1)」番目の領域となりますね。
ある緯度経度の範囲に含まれる領域
前節の指定領域抽出は、領域の通番Nを調べておく必要があります(または、領域は可変のため、ファイル毎にNを調べる)。Nが1つであれば簡単ですが、比較的広い、ある緯度経度の範囲に含まれる領域は、第3節の「最初(最後)の格子点の緯度」と「最初(最後)の格子点の経度」から、その範囲に含まれるかどうかを判定する情報処理になります。
方法は様々あると思いますが、wgrib2コマンドとLinuxのコマンドを駆使してシェルスクリプトを書いてみます。プログラミングの参考になれば幸いです。
まずは領域の「最初(最後)の格子点の緯度」と「最初(最後)の格子点の経度」を抽出します。
datafile=(250mレーダーデータのファイル)
step=(5分毎250mメッシュ全国合成レーダー降水強度GPV: 1, 高解像度降水ナウキャスト: 1-14) # 時間ステップ
tiles=$(expr 1773 \* ${step}) # 対象タイムステップまでの領域数
# 領域の「最初(最後)の格子点の緯度」
wgrib2 -grid ${datafile} | grep "lat " | head -${tiles} | tail -1773 | awk '{print $2,$4}' | nl > tile_lat
# 領域の「最初(最後)の格子点の経度」
wgrib2 -grid ${datafile} | grep "lon 1" | head -${tiles} | tail -1773 | awk '{print $2,$4}' | nl > tile_lon
tile_lat,tile_lonは、
N(1-1773),最初の経度or緯度,最後の経度or緯度
が出力されます。(緯度は北から)
指定範囲も4点の緯度経度の座標で与えるとして、その範囲に含まれる領域を以下のように判定します。
ilon=135.0 # 指定範囲の西端経度
elon=137.0 # 指定範囲の東端経度
ilat=35.0 # 指定範囲の南端緯度
elat=37.0 # 指定範囲の北端緯度
rm -f tile_num # 指定範囲に含まれる領域を格納するファイルの初期化
while read tile_lon_line ;do # tile_lonを読み込み
tile_num=$(echo ${tile_lon_line} | awk '{print $1}') # 領域N(1-1773)
tile_ilon=$(echo ${tile_lon_line} | awk '{print $2}') # 領域Nの西端経度
tile_elon=$(echo ${tile_lon_line} | awk '{print $3}') # 領域Nの東端経度
tile_elat=$(awk '($1 == '${tile_num}') {print $2}' tile_lat) # 領域Nの北端緯度
tile_ilat=$(awk '($1 == '${tile_num}') {print $3}' tile_lat) # 領域Nの南端緯度
# 指定範囲に含まれる領域の判定
if [ $(echo "${tile_elon} < ${ilon}" | bc) -eq 0 ];then # 指定範囲西端の外でない
if [ $(echo "${tile_ilat} > ${elat}" | bc) -eq 0 ];then # 指定範囲北端の外でない
if [ $(echo "${tile_ilon} > ${elon}" | bc) -eq 0 ];then # 指定範囲東端の外でない
if [ $(echo "${tile_elat} < ${ilat}" | bc) -eq 0 ];then # 指定範囲南端の外でない
echo ${tile_num} >> tile_num
fi
fi
fi
fi
done < tile_lon
指定範囲に含まれる領域の判定処理は、「領域に含まれない」の否定をif文で書いています。
あとはtile_numに出力されたNを、前節の指定領域抽出に代入して利用します。
この記事を書いた人

K.Sakurai
気象予報士/技術士(応用理学)/防災士
総合気象数値計算システムSACRA、データ提供システムCOSMOS及びお天気データサイエンスの開発に一から携わる。
WRF-5kmモデルGPV、虹予報、虹情報、1㎞メッシュ雨雪判別予測データ、2kmメッシュ推計日射量、1kmメッシュ暑さ指数 、夕焼け情報を開発。
「ビジネス活用のための気象データ基礎研修」では講師を担当。
趣味はバドミントンと登山。